
Consistent Hashing
Motivation
Cache can help us get frequetly request data fast. If we have a shared cache for a group of users, e.g. students from some university, the the size of data need to be cached is very large so we may need multiple nodes to store these data.
A naive way is to use a hash function to distribute the data to different machines, by simply adopting k%N, where k is the key of data and N is the number of nodes.
But the problem comes when we want to add server number, most data need to be moved around because the hash value changes.
To solve this problem, consistent hashing is proposed and it is widely adopted in many great systems such as Memcached and Amazon’s Dynamo.
Consistent Hashing
Goal
- How the data is assigned should be independent of the number of servers.
- Load balance
Design
The main idea is that in addition to mapping the keys, the server numbers are mapped to the same range.
This approach can be visualized on a circle. Servers and objects both hash to points on this circle; an object is stored on the server that is closest in the clockwise direction. If we want to add a server, say server 4, we need to first map server 4 into the circle, and we only need to move the part of keys(between 4 and 2) from server 3 to server 4. So that only this part of data will be influenced.
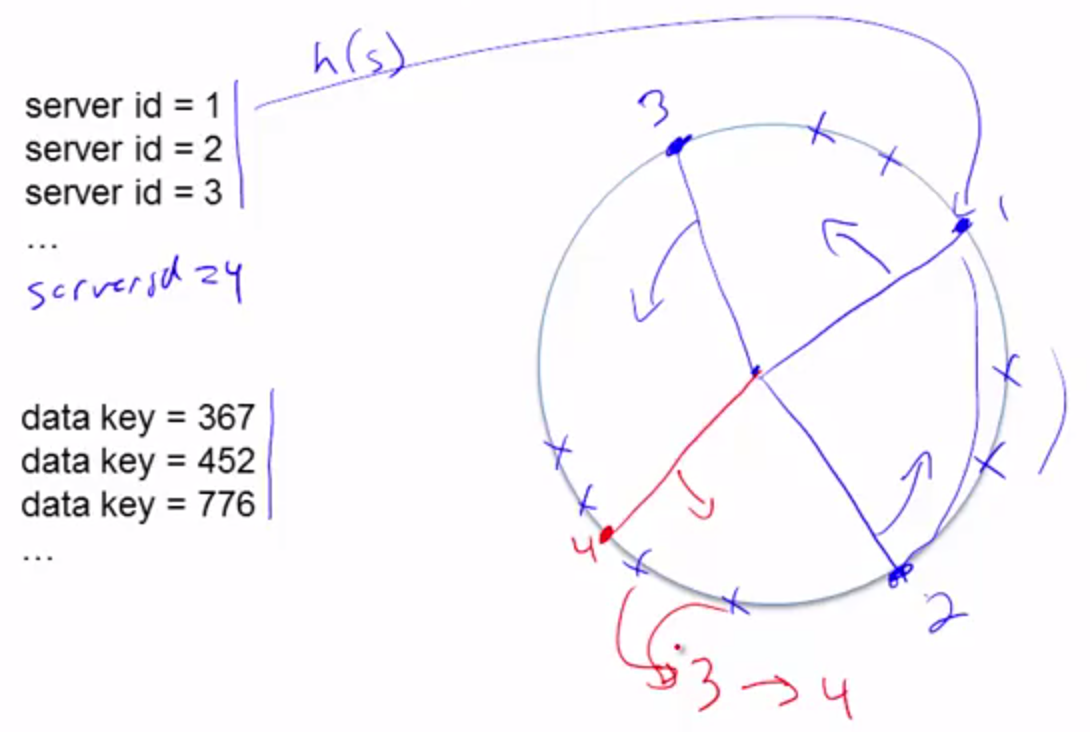
Look up and insert
Given a key k, this problem is to find the server s that minimize h(s) subject to h(s)>=h(k). One good idea is to use a balanced binary search tree, such as a Red-Black tree, to organize the servers and its corresponding hash values.
Vitual copies
When the server number is small or the load of servers differ, the partition may not be balanced.
The solution to this problem is to add vitual copies of servers. If one server is twice as big as another, it should have twice as many virtual copies.
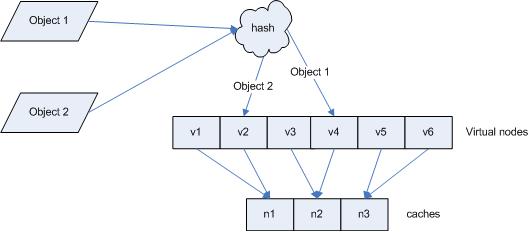
Figure from this blog