
MOOC-Data Manipulation at Scale - Note
这个MOOC是关于big data manipulation的一个overview,讲了比较多的map reduce, nosql, 以及一些经典的大数据系统。作为了解的资料挺好的,但是都是泛泛的,没有深度,适合初学者。 我喜欢作者的讲课方式,把一个技术的motivation讲的很清楚,然后慢慢带入。
Week1
第一周主要是motivation and some basic concepts.
Abstraction
今天第三次读到这个让我心花怒放的Abstraction,他说,data science最重要的两个层面:
- Matrix and Linear Algebra
- Relations and Relational Algebra
关于第一点,各种模型的输入通常是一个big matrix,无论是文本处理还是图像处理。Linear Algebra也是被Sim老师反复强调的重点。
What takes most time
There are two key observations:
- 90% of time is spent in handling the data
- 80% analytics are sum and average
关于第一点,我在尝试rumor detection这个topic的时候花了大量的时间收集和处理数据,但是真正running model的时间其实很少。
关于第二点,一个在银行做数据分析的学长向我证实了这一点。而lecture也提到了,很多模型仅仅做了aggregate就能得到很好的效果。
The cost of finding, integrating, and analyzing data, then communicating results, is the new bottleneck.
3V of Big Data
Big data itself is not necessarily the challenge, but making good use of data to discover knowledge from it is not easy.
There are 3 features of big data nowadays:
- Volumn: the size of data
- Velocity: latency of data processing
- Variety: the diversity of data sources, data format, data quality, etc.
So analyzing big data at scale with high quality is what we need to focus.
Week2
Mainly about relational database and relational algebra. 刚做过TA,所以大部分的内容还是比较熟悉的。
The main idea behind relational database is about data independence.
Relational Algebra
Each SQL query is translated into a series of raltional algebra units. They are operated with certain order.
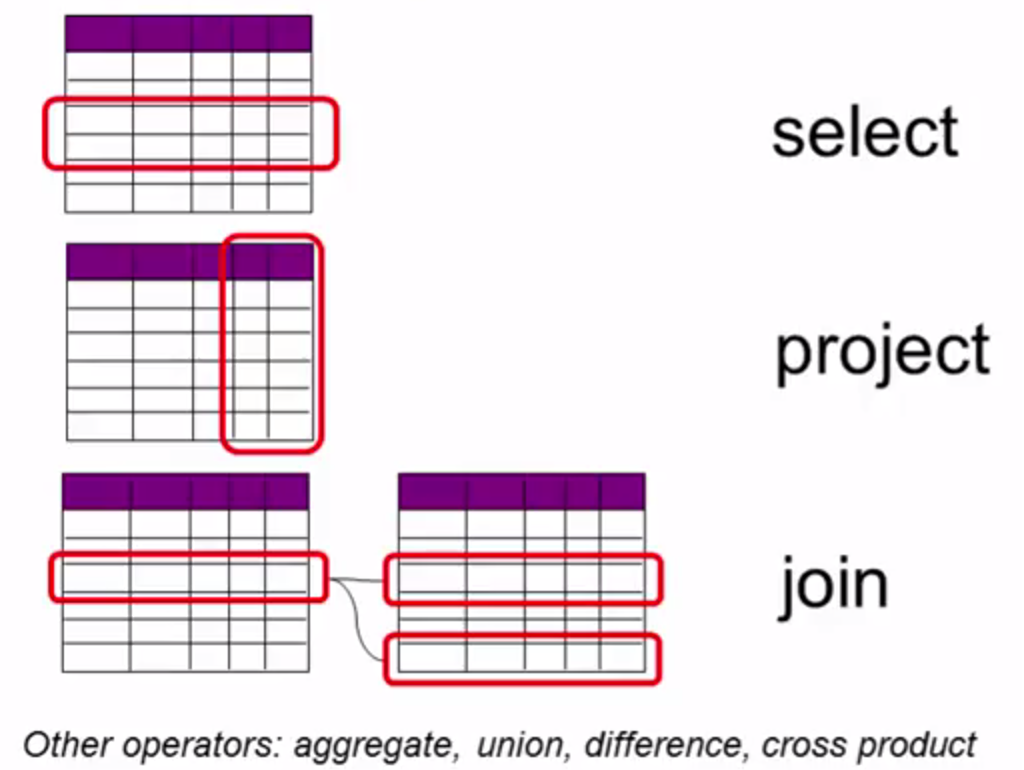

relational algebra operator
About Outer Join

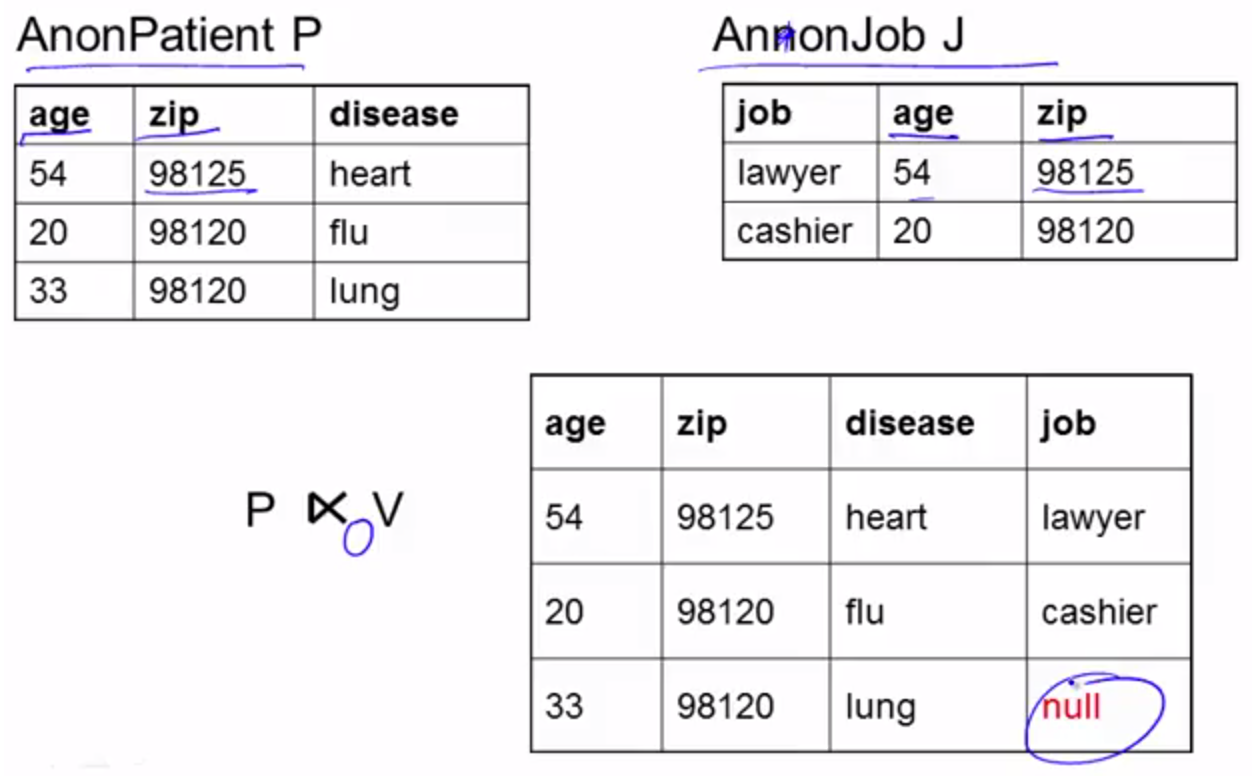
outer join
Execution Plan
Different execution plan can have quite different cost. The good thing is that commercial database will generate an optimised excution plan for your sql.
And you can also use Explain to see how your query is processed, or whether the index has been used, and so on.
Week3
About mapreduce, see post in revisit map reduce.
Distributed Query vs Parallel Query
Distributed query is to divide the query into sub-components, and process each component in distributed machines, the output of each part is then merged by a single machine. This is like just doing a map. And the single machine that process the final results can be the bottleneck.
While Parallel query process every component in parellel, e.g. map-reduce.
Week4
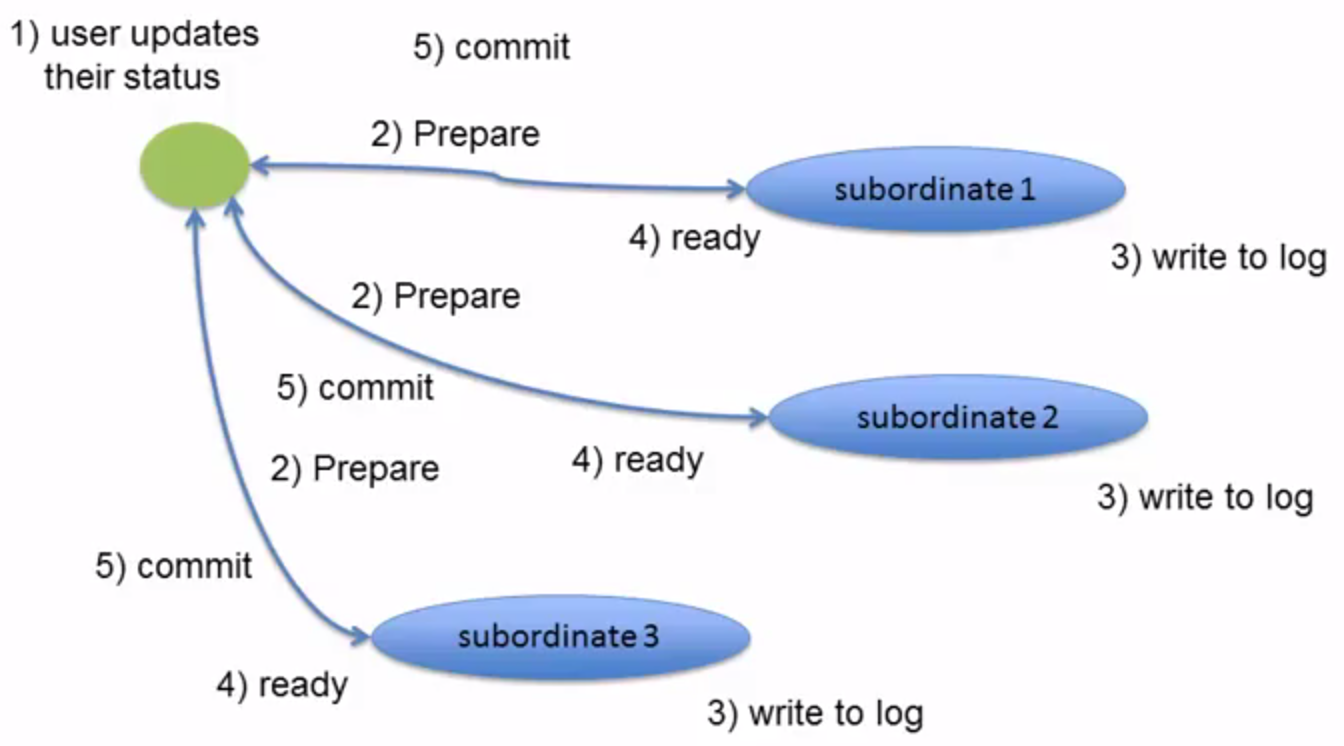
Consistency Control
The following figure is the Consistency Control mechanism of RDBMS, the disadvantage of this kind of immediate(strong) consistency is that it may takes long time, and there may be deadlocks.
Eventual Consistency
Write conflicts will eventually propagate throughout the system. Applications may read weakly consistent data and their write operation may conflicts with other applications.
CAP
- Consistency: all the users see the same data
- Availability: Can I interact with system in the presence of failure
- Partitioning: subgroups running in parallel. If yes, it may hurt consistency, if no, it may hurt availability.
Conventional database has no partitioning. And NoSQL system relaxes the consistency to achieve high availability.
NoSQL
NoSQL features
- No SQL
- No schema
- Weaker concurrency model
- High scale
Major Impact Systems
- Memcached: load everything into memory over mutiple nodes
- Dynamo: use eventual consistency to achieve high availability and scalability.
- BigTable demonstrates that persistent record storage can scale to thousands of nodes.
Memcached
Memcached is a main-memory caching service. The important concept is Consistent Hashing.
BigTable
Data Model:

The time here is used for version, when you update the record, it can keep track of the versions.
Data is sorted by row id. Then contiguous subranges of keys will be assigned to a tablet, which is the unit of distribution.
This is different from Teradata’s model. Teradata hash the keys and assign key to server in a round robin way. This is good for load balance and scalability. But if you want to get the whole range of keys, they are not stored next to each other, then it will cost more.
The pros of Teradata is the cons of bigtable, because people are more interested in recent data, then servers with recent data will be frequently accessed while those old data server is idle. To solve this problem, the tablets are moved among servers in order to get load balance.
Implementation
- column families: a group of columns
- access control: like ID number, security number, etc.
- memory accounting: allocate as a unit in memory
- disk accounting: move around in the disk as a unit
- Tablet Management

Pig
Pig is an engin to execute programs on top of Hadoop. You write a program in Pig, and it will generate a series of Map reduce tasks.
Pig simplify the process to write complicated map reduces programs.