
Revisit Map Reduce
1. Motivation
Now big data is processed with “computing clusters” instead of “super computer”.
1.1 Physical Organization of Compute Nodes
Compute nodes are organized into racks, and racks are interconnected by a switch. There are inner-rack communication and inter-rack communication.
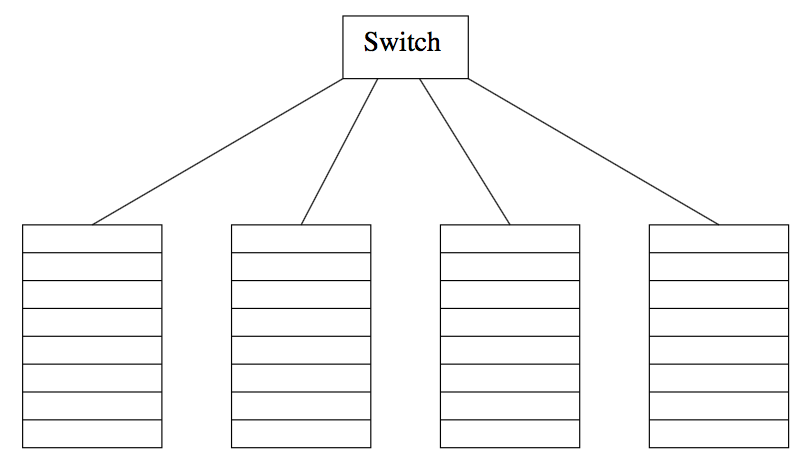
racks of computing nodes
1.2 Problem
It is likely that a single node or the entire rack is lost. We cannot just restart the entire system.
1.3 Two solutions
- Files must be stored redundantly. So that the cashes of one disk will not influence the entire system. This is about File Management. This is my previous post about HDFS.
- Computations must be divided into sub-tasks. So that if one task fails, it can restart without influencing other tasks. This is the motivation of Map Reduce.
2 Map Reduce
2.1 Map Task
- Input: one or more chunks from a distributed file system
- Output: a sequence of key-value pairs
Note that “key” can duplicate here
2.2 Grouping by Key
- Input: key-value pairs
- Output: r local files containing key-values for reduce tasks
- Process: The pairs are grouped by key, each key follows a list of values. The master controller process hash the key and put its key-value pair in one of r local files. Each file is destined for one of the Reduce tasks.
2.3 Reduce Task
- Input: one or more keys and their associated value lists.
- Output: A single file that merge the outputs from all the Reduce tasks.
A Reduce task executes one or more reducers. Reducers may be partitioned among a smaller number of Reduce tasks is by hashing the keys and associating each Reduce task with one of the buckets of the hash function.
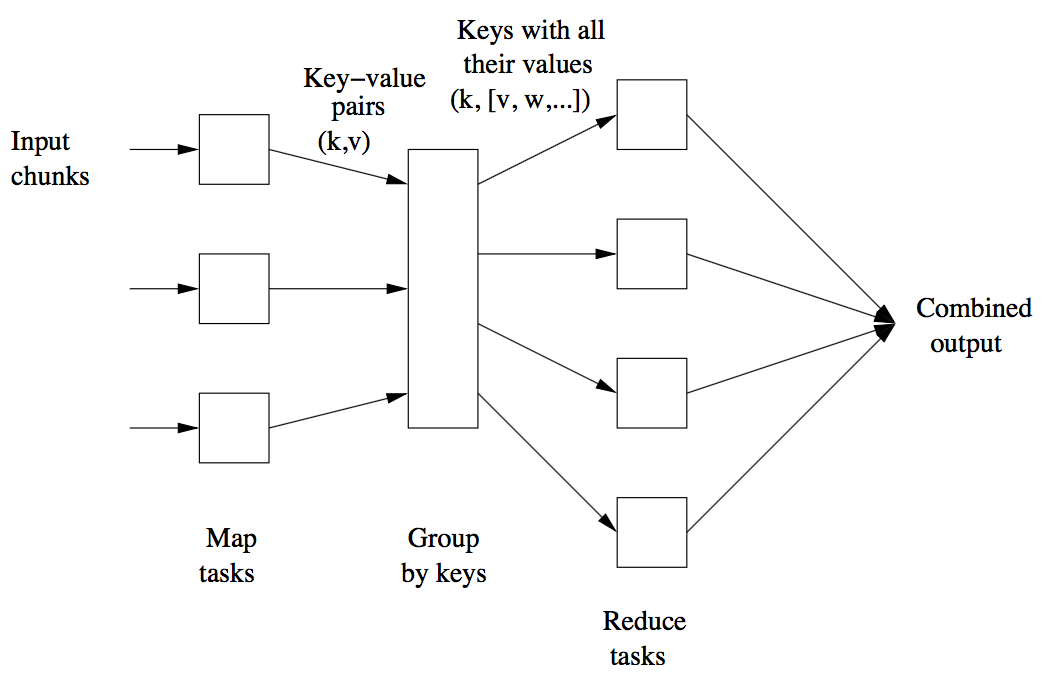
Map Reduce Computation
2.4 Combiner
For some applications such as sum and max, the result is not influenced by the order of processing, we can use Combiner to speed up the map-reduce process.
Combiner is like a local Reducer, instead of producing many pairs (w,1), (w,1),…, we could apply the Reduce function within the Map task. The pairs with key w generated by a single Map task would be replaced by a pair (w,m).
why combiner is useful?
The data trasfered to Reducer is much smaller, and thus the time used to write and read is reduced.
when combiner can not used?
For applications such as average
why it cannot replace Reducer?
Combiner only works within maps, Reducer is used to merge the output from different maps.
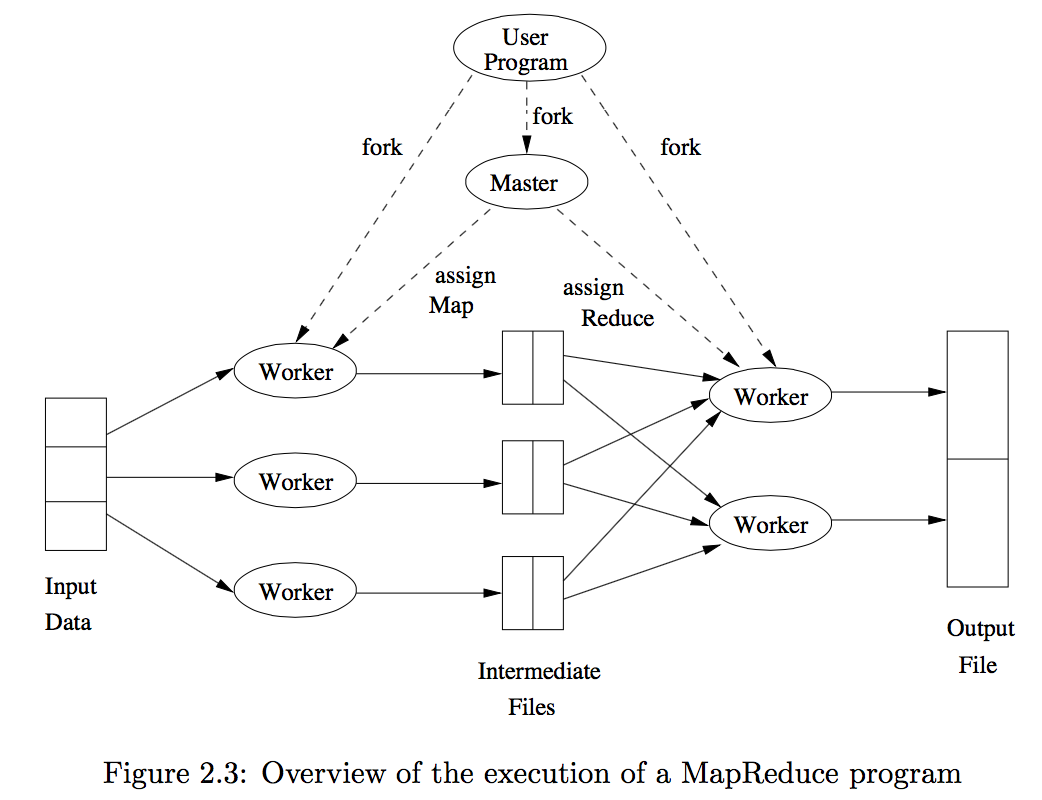
2.5 MapReduce Execution
2.5.1 Master Responsibility
- Create some number of Map tasks and some number of Reduce tasks. These tasks will be assigned to Worker processes by the Master.
It is reasonable to create one Map task for every chunk of the input file(s), but we may wish to create fewer Reduce tasks. Because each Map task create an intermediate file for each Reduce task, and if there are too many Reduce tasks the number of intermediate files explodes.
- The Master keeps track of the status of each Map and Reduce task (idle, executing at a particular Worker, or completed). A Worker process reports to the Master when it finishes a task, and a new task is scheduled by the Master for that Worker process.
2.5.2 Execution
- Each Map task is assigned one or more chunks of the input file(s) and executes on it the code written by the user.
- The Map task creates a file for each Reduce task on the local disk of the Worker that executes the Map task.
- The Master is informed of the location and sizes of each of these files, and the Reduce task for which each is destined.
- When a Reduce task is assigned by the Master to a Worker process, that task is given all the files that form its input. The Reduce task executes code written by the user and writes its output to a file that is part of the surrounding distributed file system.
2.6 Coping With Node Failures
2.6.1 Master Node Failure
Restart the entire map-reduce job
2.6.2 Map Worker Node Failure
It can be detected by Master since master periodically pings the workers.
If fail, two steps are needed
- Redone the Map Task. The Master sets the status of each of these Map tasks to idle and will schedule them on a Worker when one becomes available.
- And the Master need to inform the Reducer Task that its input from Map Task has been changed.
Note that the map tasks assigned to this worker need to be redone even when the task has been completed. This is because the map output is stored in this failed node and is now unreachable to the reducer task.
2.6.3 Reduce Worker Node Failure
Redone: The Master simply sets the status of its currently executing Reduce tasks to idle. These will be rescheduled on another reduce worker later.
3. Algorithms using Map-Reduce
3.1 Selections
σ_C(R) can be done most conveniently in the map portion alone.
- The Map Function: For each tuple t in R, test if it satisfies C. If so, produce the key-value pair (t, t). That is, both the key and value are t.
- The Reduce Function: The Reduce function is the identity. It simply passes each key-value pair to the output.
3.2 Projection
Projection is similar to selection, except that we need to remove duplication in reduce task. π_S(R):
- Map: For each tuple t in R, construct tuple t’ with attributes in S, output (t’, t’).
- Reduce: turns (t’,[t’,t’,…, t’]) into (t’, t’)
Note that we can also include a combiner in the map task.
3.3 Union, Intersection and Difference
Consider relation R and S with same schema.
For Union, Map generates (t,t), and Reduce eliminates duplicates.
For Intersection, Map generates (t,t), and Reduce only outputs (t,[t,t]), i.e. with tuples from both relations.
For Difference R-S, Map generates either (t,R) or (t,S), and Reduce only outputs (t,[R])
3.4 Natural Join
The main idea is to use the common attribute as the key, and merge the tuples from two relations that share this attribute value. For R(a,b) and S(b,c),
- Map: generate either (b,(R,a)) or (b,(S,c))
- Reduce: merge (b,[(R,a),(S,c)]) into (a,b,c)